

TrustML project
Project coordinator
Prof. Battista Biggio
PRA Lab – University of Cagliari
Duration
25 Months
September 2022 – October 2024
Budget
Total budget: 52777.78 €
FDS funded budget: 52777.78 €
People involved
Prof. Giorgio Giacinto
Prof. Giorgio Fumera
Prof. Luca Didaci
Prof. Matteo Fraschini
Funding
Project context and challenges
Machine learning (ML) and Artificial intelligence (AI) have recorded unprecedented success in different applications, including computer vision, speech recognition, and natural language processing.
Despite providing accurate predictions, such models suffer from several limitations which prevent their applicability in security-sensitive and safety-critical domains.
In this project, we aim to address three main challenges that are hindering the development of trustworthy AI/ML models in these domains.

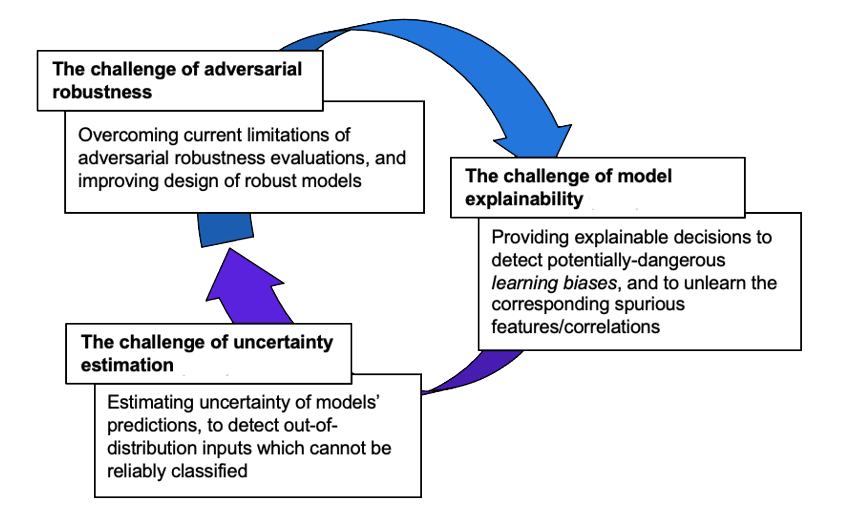
1. The challenge of adversarial robustness
2. The challenge of model explainability
3. The challenge of uncertainty estimation
The first is the challenge of adversarial robustness. AI/ML models have been shown to be vulnerable to adversarial examples, i.e., carefully optimized perturbations added to the input images, text, or audio. Evaluating robustness in other domains, like malware detection, remains an open challenge due to the lack of a proper formalization of the feasible, structural, and more complex input manipulations specific to such domains.
The second is the challenge of model explainability. AI/ML models output predictions which are hardly interpretable; it is difficult to identify which features of the input samples contribute to predicting them within a given class, or which training samples support such a decision. Explainability is a desirable property not only to build users’ trust in AI/ML, but also to understand what models learn, enabling detection and mitigation of potential dataset/model biases.
The third challenge is about evaluating uncertainty. It arises from the fact that AI/ML models can output highly confident predictions even when the input data is outside the support of the training data distribution, as in the case of adversarial examples.
These problems have been addressed by the development of appropriate scientific methodologies allowing a significant advancement of the state of the art. The methodological advancement concerned:
– the development of techniques for evaluating the robustness/safety of machine learning algorithms with respect to inputs disrupted to compromise their decisions, known as adversarial examples;
– the development of techniques for improving the robustness of algorithms against these inputs.
– the development of techniques to improve the interpretability of the decisions provided by these algorithms.
A large collection of datasets for the experimentation on use cases was performed, followed by the development and testing of prototype systems on applications of interest, which included image recognition and automatic detection of computer viruses.
Project results and impact
The project produced significant tangible results, including (i) scientific publications published in international journals and in the proceedings of conferences among the most important in the field of machine learning and artificial intelligence; (ii) the release of benchmark datasets and associated experimental prototypes, through the production of various projects with open code source; (iii) an intense dissemination and communication activity towards stakeholders and the scientific community.
The project has also fostered numerous scientific collaborations at national and international level, such as demonstrated by the number of publications with co-authors external to the project unit team. This led to the consolidation and formalization of agreements for carrying out some joint activities with companies and international institutions.
Publications
- G. Floris, R. Mura, L. Scionis, G. Piras, M. Pintor, A. Demontis, and B. Biggio. Improving fast minimum-norm attacks with hyperparameter optimization. In ESANN, 2023.
- R. Mura, G. Floris, L. Scionis, G. Piras, M. Pintor, A. Demontis, G. Giacinto, B. Biggio, and F. Roli. HO-FMN: Hyperparameter optimization for fast minimum-norm attacks. Neurocomputing, 616:128918, 2025.
- A. E. Cinà, K. Grosse, A. Demontis, S. Vascon, W. Zellinger, B. A. Moser, A. Oprea, B. Biggio, M. Pelillo, and F. Roli. Wild patterns reloaded: A survey of machine learning security against training data poisoning. ACM Comput. Surv., 55(13s):294:1–294:39, jul 2023.
- K. Grosse, L. Bieringer, T. R. Besold, B. Biggio, and K. Krombholz. Machine learning security in industry: A quantitative survey. IEEE Transactions on Information Forensics and Security, 18:1749–1762, 2023.
- H. Eghbal-Zadeh, W. Zellinger, M. Pintor, K. Grosse, K. Koutini, B. A. Moser, B. Biggio, and G. Widmer. Rethinking data augmentation for adversarial robustness. Information Sciences, 654:119838, 2024.
- M. Pintor, L. Demetrio, A. Sotgiu, H.-Y. Lin, C. Fang, A. Demontis, and B. Biggio. Detecting attacks against deep reinforcement learning for autonomous driving. In International Conference on Machine Learning and Cybernetics, ICMLC. IEEE SMC, 2023.
- B. Montaruli, L. Demetrio, M. Pintor, L. Compagna, D. Balzarotti, and B. Biggio. Raze to the ground: Query-efficient adversarial HTML attacks on machine-learning phishing webpage detectors. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, AISec ’23, pages 233–244, New York, NY, USA, 2023. ACM.
- D. Trizna, L. Demetrio, B. Biggio, and F. Roli. Nebula: Self-attention for dynamic malware analysis. IEEE Transactions on Information Forensics and Security, 19:6155–6167, 2024.
- L. Minnei, H. Eddoubi, A. Sotgiu, M. Pintor, A. Demontis, and B. Biggio. Data drift in android malware detection. In International Conference on Machine Learning and Cybernetics, ICMLC. IEEE, 2024 (in press).
- W. Guo, A. Demontis, M. Pintor, P. P. K. Chan, and B. Biggio. LFPD: Local-feature-powered defense against adaptive backdoor attacks. In International Conference on Machine Learning and Cybernetics, ICMLC. IEEE, 2024 (in press).
- E. Ledda, D. Angioni, G. Piras, G. Fumera, B. Biggio, and F. Roli. Adversarial attacks against uncertainty quantification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 4599–4608, October 2023.
- G. Faa, M. Castagnola, L. Didaci, F. Coghe, M. Scartozzi, L. Saba, and M. Fraschini. The Quest for the Application of Artificial Intelligence to Whole Slide Imaging: Unique Prospective from New Advanced Tools. Algorithms. 2024; 17(6):254.
- M. Fraschini, M. Castagnola, L. Barberini, R. Sanfilippo, F. Coghe, L. Didaci, R. Cau, C. Frongia, M. Scartozzi, L. Saba, and G. Faa. An Unsupervised Learning Tool for Plaque Tissue Characterization in Histopathological Images. Sensors. 2024; 24(16), 5383.
- L. Didaci, S. M. Pani, C. Frongia, and M. Fraschini. How Time Window Influences Biometrics Performance: An EEG-Based Fingerprint Connectivity Study. Signals 2024; 5, 597-604.
- Silvia Lucia Sanna, Diego Soi, Davide Maiorca, Giorgio Fumera, Giorgio Giacinto, A risk estimation study of native code vulnerabilities in Android applications, Journal of Cybersecurity, Volume 10, Issue 1, 2024, tyae015.
Preprints (under review)
- D. Gibert, L. Demetrio, G. Zizzo, Q. Le, J. Planes, and B. Biggio. Certified adversarial robustness of machine learning-based malware detectors via (de)randomized smoothing. arXiv e-prints, 2024.
- L. Demetrio and B. Biggio. secml-malware: Pentesting Windows malware classifiers with adversarial EXEmples in Python. arXiv e-prints, 2024.
- A. E. Cinà, F. Villani, M. Pintor, L. Schönherr, B. Biggio, and M. Pelillo. σ-zero: Gradient-based optimization of L0-norm adversarial examples. ArXiv e-prints, 2024.
- G. Piras, M. Pintor, A. Demontis, B. Biggio, G. Giacinto, and F. Roli. Adversarial pruning: A survey and benchmark of pruning methods for adversarial robustness. arXiv e-prints, 2024.
- E. Ledda, G. Scodeller, D. Angioni, G. Piras, A. E. Cinà, G. Fumera, B. Biggio, F. Roli. On the Robustness of Adversarial Training Against Uncertainty Attacks. arXiv e-prints, 2024.
Open source software & Prototypes
- SecML-Torch is an open-source Python library designed to facilitate research in the area of Adversarial Machine Learning and robustness evaluation. The library provides a simple yet powerful interface for generating various types of adversarial examples, as well as tools for evaluating the robustness of machine learning models against such attacks.
- SecML-malware is a Python library for creating adversarial attacks against Windows Malware detectors. Built on top of SecML, SecML Malware includes most of the attacks proposed in the state of the art. We include a pre-trained MalConv model trained by EndGame, used for testing.
- Adversarial Pruning Benchmark is a framework to categorize adversarial pruning methods and evaluate them under a novel, fair evaluation protocol. It contains an empirical re-evaluation of current adversarial pruning methods and is open to new submissions as a public benchmark.
- HO-FMN is the implementation of the method for optimizing the hyperparameters of the Fast Minimum-Norm (FMN) attack FMN. The FMN version used here is implemented in PyTorch and is modular, meaning that one can select the loss, the optimizer, and the scheduler for the optimization.
- Sigma-zero is the official PyTorch implementation of the σ-zero: Gradient-based Optimization of ℓ0-norm Adversarial Examples.
- Raze to the Ground is the source code of the paper “Raze to the Ground: Query-Efficient Adversarial HTML Attacks on Machine-Learning Phishing Webpage Detectors” accepted at the 16th ACM Workshop on Artificial Intelligence and Security (AISec ’23), co-located with ACM CCS 2023.